# Clinical MDR Database Architecture
This document holds the design documentation for the OpenStudyBuilder database architecture - named as the Clinical MDR database component.
The database is implemented as a linked graph database in Neo4j, and the solution design utilizes a number of capabilities uniquely supported by the label property graph model.
# Modelling guidelines
# General guidelines
# Nodes
Entities are the nouns in the business questions :
- What ingredients are used in a recipe ?
- What term is used by an objective template ?
These entities will be represented by nodes, and :
- The generic nouns often become labels in the model
- Use domain knowledge deciding how to further group or differentiate entities
# Node properties
Property lookups have a cost, and parsing complex properties adds even more cost. Therefore, properties used as filters / anchors for traversal (starting points in a path) should be as simple as possible : strings, numbers, boolean, dates.
Also, properties used as filters in common queries should have an index on them to increase performance.
Finally, if a property is unique throughout the graph for a given label (e.g. the unique identifier of a study), then a uniqueness constraint should be created on that property. Note that this automatically creates an index on that property.
Note : In the Neo4j database, existence constraints also exist, preventing a node being created without a given property, but these are not enforced in this project.
# Node label vs property
Sometimes, the questions arises of : should this value be a property or a node label ? For example, a Concept node in the MDR domain model can have a second type, like "Activity" or "CompoundDosing". This could be both a property "type=Activity", or an additional label on the node ":Concept:Activity".
The general guidance is :
- If all the nodes with the main label (Concept) have a value for this property
- And if the set of possible values is identified
- And if the set of possible values is small and the cardinality is high
=> You can use a label.
Otherwise, use a property.
# Relationships
Relationships are the verbs in the business questions :
- What ingredients are used in a recipe ?
- What term is used by an objective template ?
It is recommended to use verbs and not nouns for the relationship types ; and to avoid symmetric relationships (e.g. USES and USED_BY). Except if the relationship is inherently non-symmetric (e.g. Mikkel FOLLOWS Anja is not the same as Anja FOLLOWS Mikkel). The direction of the relationships is based on the expected business questions.
Follow the same rules for relationship properties as for node properties. Note : This project does not have many properties on relationships because in past versions of Neo4j, relationship properties could not be indexed ; but this is now possible since version 4.3.
# Intermediate nodes
Sometimes, a relationship - and its properties - between two nodes is not enough to store all the information and the context needed.
For example, in the MDR domain model, a Study has Endpoints, which can be shared between multiple Studies. But in the context of a given Study, an Endpoint has a Unit, which can be different in the other Studies that also have this Endpoint. So here, connecting the Endpoint to the Unit is not enough, because it would be connected to multiple Unit nodes, and how can we know for which Study each of these relationships are for ?
This is where we introduce intermediate nodes : in our case, the complete path is like this : (:Study)-->(:StudyEndpoint)-->(:Endpoint) ; and the (:StudyEndpoint) node has a relationship to its (:Unit).
# Versioning
# Node versioning
On a basic level, versioned nodes are split into two types of nodes :
- A root node (e.g. StudyRoot) ; this node contains all the immutable properties (e.g. its uid)
- A value node (e.g. StudyValue) ; this node contains all the mutable properties (e.g. its name)
Between each pair of nodes (the Root and one of its Value nodes), there is a HAS_VERSION relationship, containing the versioning information :
- start_date
- end_date (not present when open)
- version (metadata version)
- status (Draft, Final, Retired)
- change_description
- author_id
Additional relationships also exist as "shortcuts" for
- LATEST_FINAL (most recent version with status Final)
- LATEST_DRAFT (most recent version when in Draft status)
- LATEST_RETIRED (most recent when in Retired status)
- LATEST (most recent independent of status)
The implementation of versioning is made to also support the global audit trail functionality simply by querying the HAS_VERSION relationships.
# Versioning of Library Elements
In the library module all standard elements are versioned individually as root-value node pairs. Thereby all unique versioned value nodes are only represented once in the database. All objects maintained in the library part of the system are therefore supported by fine granular versioning of data standards elements.
For data standard elements imported from CDISC Library a similar versioning approach is applied only representing the unique value pairs in the system applying the versioning information and dates from the source system (the CDISC Library).
Version independent relationships can be made to the root node of a library standard element and versioned relationships can be made to the value nodes.
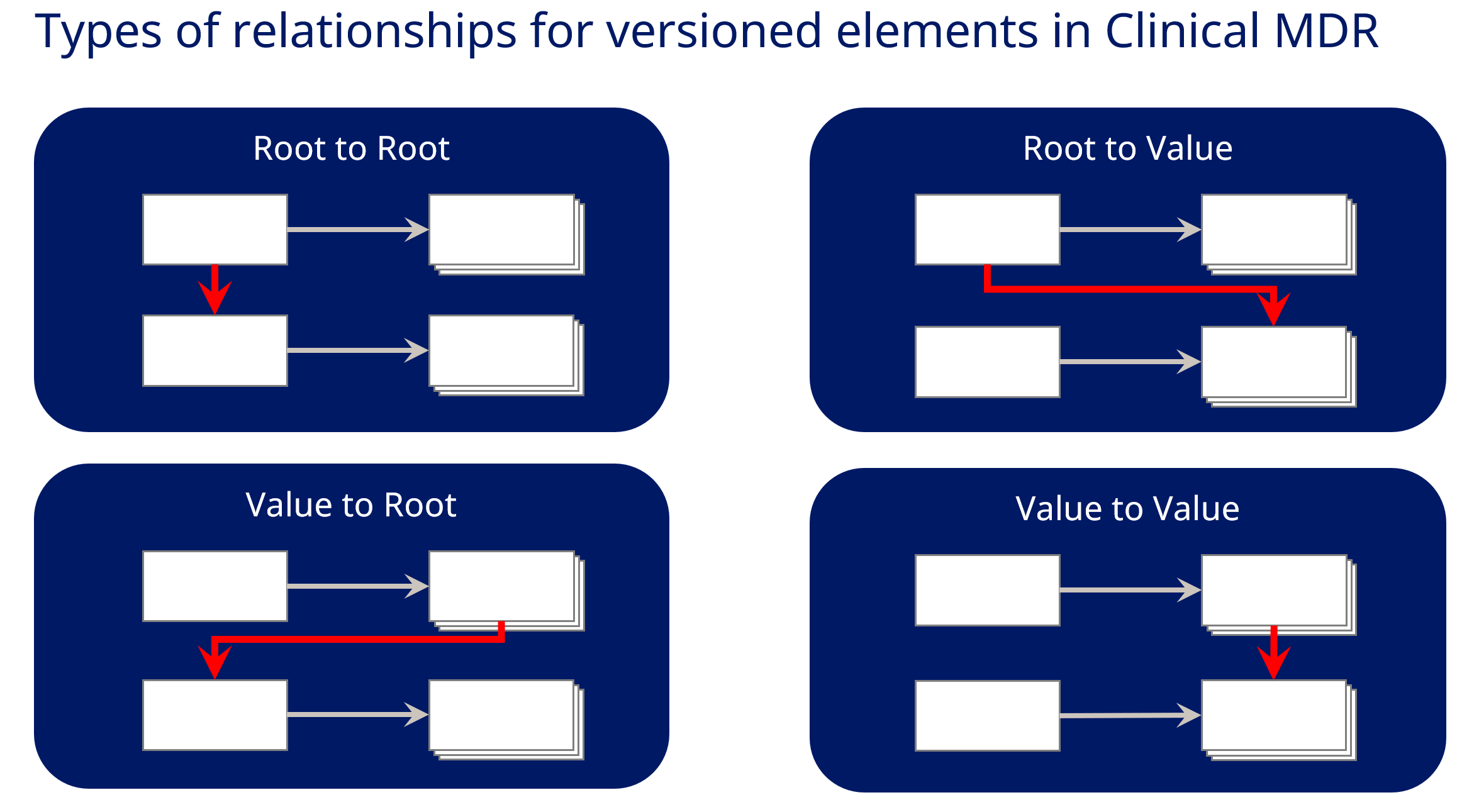
Root to Root Relationship
- Relationship independent of versioning.
- => All versions of the source object are connected to the latest version of the target object (virtually).
- Sample: Grouping of Criteria templates to Criteria Type CT Term.
Root to Value Relationship
- Relationship from Root to other Value node than the root-value pair, so source node independent of versioning.
- Currently not relevant
Value to Root Relationship
- Relationship from specific source node version to independent target node.
- => A specific version of the source object is connected to the latest version of the target object (virtually). Cascading of relationship must be handled when a new version of the source is created.
- Sample: Syntax Template and their instances to their TemplateParameters. This allows to keep track of the parameters used in the previous versions of the syntax template instance, but the version of the parameter will always be the latest one.
Value to Value Relationship
- Relationship is version-aware on both sides.
- Cascading of relationship must be handled when changes happened on either the target or source nodes.
- Sample: Relationship between Objective Syntax Templates and Objective Instantiations .
# Versioning of Studies
In the study module the versioning is applied at the study level as study root-value node pairs. A specific version of a study will thereby have outbound relationships to all detailed study definitions as study fields and study selections.
All data definitions done for a study are related to a StudyAction node capturing the before and after state. This is to support the detailed audit trail capabilities for all create, update and deletes done for a study as well as the release (minor version), locking (major version), unlock (new version).

For more information on the study versioning see also the Maintain Study Status and Versioning user guide.