# API architecture
This document describes the architecture of the Clinical MDR API service component.
# API Documentation
OpenAPI specification of the Clinical MDR API is accessible at /api/docs path for each target environment,
for example https://openstudybuilder.northeurope.cloudapp.azure.com/api/docs.
# General Testing Approach
We differentiate between those tests that need external components (like an API or a database) and those that run without any additional setup.
This is reflected in the folder structure as follows:
tests/unit: no additional/external components are needed to run the tests.tests/integration: there are external components that need to be set up before the tests can run.
# Unit Tests
The foundation of the testing is made up by a lot of small and fast unit tests.
A unit is in most of the cases a single function or method.
In rare cases a unit may also be considered to be a class or a slightly different concept.
The unit tests typically call the function with potential parameters and ensures that the outcome/response is as expected.
# Code Structure
There are three building blocks that every unit test should make use of:
- Given
- When
- Then
Each unit test is structured in a way, so that these building blocks are clear on the first sight. E.g.:
def test__approve__in_draft_status__set_to_final():
# given
objective = new Objective(status='Draft')
# when
objective.approve()
# then
assertThat(objective.getStatus() == 'Final')
# Integration Tests
# Current Approach to Testing
This section describes what is our current approach of implementing automated testing by pytest.
# Integration Tests Guidelines
# Assertion
To ensure the function is working correctly, we assert the actual output with the expected output.
Example of a simple test by assertion:
import unittest
class TestSum(unittest.TestCase):
def test_list_int(self):
data = [1, 2, 3]
result = sum(data)
self.assertEqual(result, 6)
# Setup Test Data
Most of the time, it is needed to set up a test database in order to perform our test. Our current approach is to call existing service to create a test database instead of writing a full cypher query.
This way we can make use of existing service and for easy maintenance.
For easy and fast set up of a test database, a method_library has been made to gather all the methods for setting up different components of required test database, that the developer can choose from.
The method library can be found in:
.
├── ...
└── clinical_mdr_api
├── ...
└── tests
├── ...
└── integration
├── ...
└── utils
├── ...
└── method_library.py
# Maintain method_library.py
- For easier maintenance, several factory files is made next to the method_library, for grouping of methods. i.e. factory_epoch for containing methods related to creating epochs.
- All methods from the factory files should be imported to method_library, so it act as a centralised place for all methods to create test database.
- All methods should be called from method_library instead of directly from factory files.
# Previous Approach to Testing
The previous approach for integration tests was mainly using the router level (and a TestClient included in FastAPI package). This actually creates a HTTP Requests to proper URL and compares results with expectations. For that a helper class has been created:
clinical_mdr_api.tests.utils.api.APITest
This class can be used as a base class for particular TestCase class (it already inherits from unittest.TestCase). The configuration includes:
self.SCENARIO_PATHS # list of paths of scenario files
self.setUp() # method to properly setup test scenario also in cls.setUpClass version
Scenario files can be found in
clinical_mdr_api/tests/data/scenarios/$
directory.
General schema for json scenario configuration:
[
{
"request": {
"headers": {},
"url": "/libraries/",
"request": {},
"method": "GET"
},
"response": {
"headers": {},
"result": [],
"code": 200,
"save": {
"uid": "uid"
},
"length": 0
}
}
]
request - describes request parameters
- headers - request headers
- url - request url
- method - request method ("POST", "GET", "PATCH" is now supported)
- request - request body
response
- headers - expected headers
- result - optional value for checking contents of response
- code - expected response code
- save - optional value allowing saving item from response for later use in scenario
- length - optional value for response json length checking
# Acceptance tests
We use Pytest-BBB for writing acceptance tests based on Gherkin features.
Pytest-BDD is based on pytest and allows almost everything that is possible with pytest.
Documentation: https://pytest-bdd.readthedocs.io/en/stable/#welcome-to-pytest-bdd-s-documentation
To run the acceptance tests you just need to execute the pytest command as you would do for unit tests:
$ pytest
# REST API Guidelines
In general, we are following Zalando RESTful API Guidelines (opens new window).
# HTTP Methods
This is the default usage of the HTTP Methods:
| Method | Usage | Success Response Code |
|---|---|---|
| GET | Get existing - Returns a single entity or a list of entities. This is read only. | 200 - OK |
| POST | Create new - Creates a new entity or multiple new entities. This is non-idempotent. Responses can be cached. | 201 - Created |
| PUT | Overwrite entirely - Overwrites an existing or multiple existing entities entirely. Does not create a new entity (use POST in this case). This is idempotent. Responses cannot be cached. | 200 - OK |
| PATCH | Update partially - Updates some part of an existing entity or multiple existing entities. | 200 - OK |
| DELETE | Delete existing - Soft deletes an existing or multiple existing entities. The previues state is still available in the database for Audit trail usage. | 204 - No Content |
E.g.:
| Resource | GET - read | POST - create | PUT - overwrite | PATCH - Update partially | DELETE - delete |
|---|---|---|---|---|---|
| /studies | Returns a list of study objects. | Creates a new study. | Bulk update of studies where each study will be completely overwritten. | Bulk update of studies where each study will only modified with the provided parameters. | Deletes all studies. |
| /studies/xyz | Returns the specific study identified by 'xyz'. | Method not allowed (405). | Overwrites the entire study identified by 'xyz'. | Updates only the specified parts of the study identified by 'xyz' | Deletes the study identified by 'xyz'. |
# API Conventions
# Paths
- We use only nouns in URLs (preferrably in plural form). The API describes resources, so the only place where actions should appear is in the HTTP methods.
- Endpoints names should be specified in
kebab-case(lowercase). - We avoid deep nesting of the endpoints if possible.
- We minimize the number of root endpoints.
- Every endpoint must contain a description string describing its functionality.
- Endpoint parameters (path/query/body fields) should be explicitly typed.
- We avoid PUT requests if possible.
- We have a unified method of pagination for query results.
E.g.
- GET
/concepts/unit-definitions - GET
/studies/{uid}/study-disease-milestones/{study_disease_milestone_uid}
# Query Parameters
- Parameter names and variables should be specified in
snake_case. - Parameter abbreviations like
UIDshould contain a prefix of the referenced entity type, e.g.study_uid. - Each parameter should explicitly state whether it is
required,optionaland/ornullable.
E.g.
- GET /studies?page_number=1&page_size=10
# Body (JSON payloads)
- Fields should be specified in
snake_case. - Each field should explicitly state whether it is
required,optionaland/ornullable.
# Error Handling
During processing of http requests, different types errors may be detected and reported to consumers. Broadly speaking, they fall into the following categories:
Validation errors detected and reported by the Pydantic library (an underlying component of FastAPI), resulting in HTTP response status
422. Pydantic will perform validation of query/path/body fields based on the validation rules we specify for each of these fields, instead of us raising explicit exceptions in our code.Example guides on how to use Pydantic validation of query/path/body fields:
- https://fastapi.tiangolo.com/tutorial/query-params-str-validations/
- https://fastapi.tiangolo.com/tutorial/path-params-numeric-validations/
- https://fastapi.tiangolo.com/tutorial/body-fields/
Example response when required fields in the POST payload are not supplied:
{ "detail": [ { "loc": [ "body", "name" ], "msg": "field required", "type": "value_error.missing" }, { "loc": [ "body", "activity_item_class_uid" ], "msg": "field required", "type": "value_error.missing" }, { "loc": [ "body", "library_name" ], "msg": "field required", "type": "value_error.missing" } ] }
Validation errors raised by our code when our business rules or additional validation constraints (not handled by Pydantic) are unmet, resulting in HTTP response status
400.- Example response when API consumer tries to create an entity with the same name as the name of an already existing entiry of same type:
{ "type": "ValidationException", "message": "Library 'SNOMED' already exists", "time": "2023-05-16T07:33:40.888526", "path": "http://localhost:8000/libraries", "method": "POST" }
- Example response when API consumer tries to create an entity with the same name as the name of an already existing entiry of same type:
"Not found" errors raised by our code when a referenced entity does not exist, resulting in HTTP response status
404.- Example response:
{ "type": "NotFoundException", "message": "CompoundAR with uid XYZ does not exist or there's no version with requested status or version number.", "time": "2023-05-16T07:34:43.330141", "path": "http://localhost:8000/concepts/compounds/XYZ", "method": "GET" }
- Example response:
Authenthication/Authorization erros
Example 1:
Bearertoken not suplied in theAuthorizationheader, resulting in response status401// Example to be added laterExample 2: The supplied
Bearertoken does not contain the required permissions for the requested endpoint, resulting in response status403// Example to be added later
# Code Style
- We should follow the rules mentioned here: https://pep8.org.
- All code must be formatted using Black (opens new window) and isort (opens new window) tools (run
pipenv run formatto auto-format all code). - All code must pass Pylint (opens new window) static code analysis. Pylint rules which we are globally ignoring are stored in the pyproject.toml file.
# Introduction to neomodel extension
Neomodel (opens new window) is an object graph mapper (OGM) library for the Neo4j database. The object graph mapper is a tool that maps python objects into neo4j nodes and relationships. It allows to write a python code which is under the hood translated into cypher queries and later on executed in the neo4j graph database. It means that with neomodel we can implement more robust python code that doesn't require to include raw cypher queries in python implementation.
# Neomodel drawbacks
When we started to use neomodel to implement database queries, we have noticed that we can easily get performance issues because neomodel doesn't support returning many nodes and relationships in one database query. Let's take for instance a StudyVisit nodes that contain many relationships to different nodes like controlled terminology terms, simple concepts or studies.
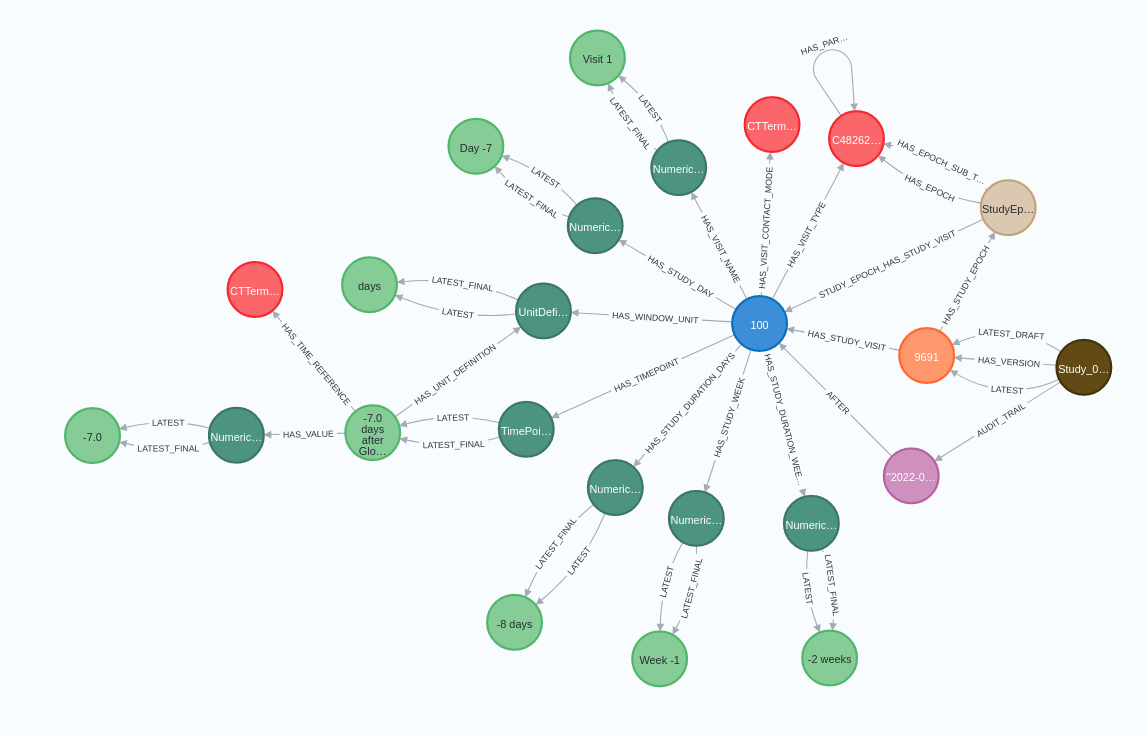
The image posted above describes all the data that is needed to build a single study visit object. From neomodel perspective it means that to retrieve these nodes from the database we have to execute more than 10 database calls to construct a single study visit object as neomodel lacks a possibility to traverse many relationships in a one database query.
# Neomodel extension
To solve this issue we have developed the neomodel extension module. Its main advantage is that we can still write a python neomodel code that retrieves data from the database but in the same time it can traverse many relationships in a single database call. We can return all of the data listed in the figure above in the single database call. If we have to return for instance 50 study visits which is a case for some studies, we don't have to execute around 50 x 10 database calls like it's done in the pure neomodel library, but we can retrieve everything that is needed to construct 50 study visitis in a single database query but still using python code.
# Exemplary neomodel query
The following piece of code is the neomodel extension implementation of the query that returns the data necessary for all the study visits from a given study.
`def find_all_visits_by_study_uid(self, study_uid: str) -> Sequence[StudyVisitOGM]:
all_visits = [
StudyVisitOGM.from_orm(sas_node)
for sas_node in StudyVisitNeoModel.nodes.fetch_relations(
"study_epoch_has_study_visit__has_epoch",
"has_visit_type",
"has_visit_contact_mode",
"has_visit_name__has_latest_value",
"has_after",
)
.fetch_optional_relations(
"has_window_unit__has_latest_value",
"has_timepoint__has_latest_value__has_unit_definition__has_latest_value",
"has_timepoint__has_latest_value__has_time_reference",
"has_timepoint__has_latest_value__has_value__has_latest_value",
"has_study_day__has_latest_value",
"has_study_duration_days__has_latest_value",
"has_study_week__has_latest_value",
"has_study_duration_weeks__has_latest_value",
"has_epoch_allocation",
)
.filter(has_study_visit__study_root__uid=study_uid, is_deleted=False)
.order_by("unique_visit_number")
.to_relation_trees()
]
return all_visits`
It proves that we can actually traverse many relationship in a single query. The following points will describe the neomodel extension syntax used to build the above query:
- The double underscode __ notation reflects a next level of relationship that is being traversed.
- StudyVisitNeomodel is a neomodel OGM class that is used by the neomodel library to convert python instances into neo4j concepts.
- StudyVisitOGM if a pydantic BaseModel that knows how to map the neomodel extension output into BaseModel object. Thanks to this, we can directly map the database output into the API model which is returned to the client.
- fetch_relations is a section that contains all the required relationships that have to be traversed to build a study visit object
- fetch_optional_relations is a sections that contains all the optional relationships that may exist for some study visits but they are not required
# Pylint
Pylint is a static code analyser for Python.
Pylint analyses your code without actually running it. It checks for errors, enforces a coding standard, looks for code smells, and can make suggestions about how the code could be refactored.
Pylint can infer actual values from your code using its internal code representation (astroid). If your code is importing logging as argparse, Pylint will know that argparse.error(...) is in fact a logging call and not an argparse call.
Pylint Documentation (opens new window)
# Run Pylint
To run Pylint you can execute the following command which will analyse the entire codebase and output results:
pipenv run lint
or run the following command to save the report to a file:
pipenv run lint > linting_report.txt
Build pipeline (opens new window) is running this linting check as one of the first steps, and the whole build job will fail if Pylint reports any issues.
# pyproject.toml
pyproject.toml (opens new window) is the file where we define custom settings for Pylint and other tools used in our project.
Sections related to Pylint are marked with [tool.pylint.'<setting>'], where '<setting>' refers to a Pylint setting that we wish to customize.
# VS Code
To integrate Pylint with VS Code you will need to install the Python Extension (opens new window) which comes with Pylint out of the box.
When installation is done, VS Code will automatically detect the pyproject.toml configuration file and start analysing our code as you write.
Any issues found by Pylint in the opened files will be shown in the PROBLEMS tab, e.g.
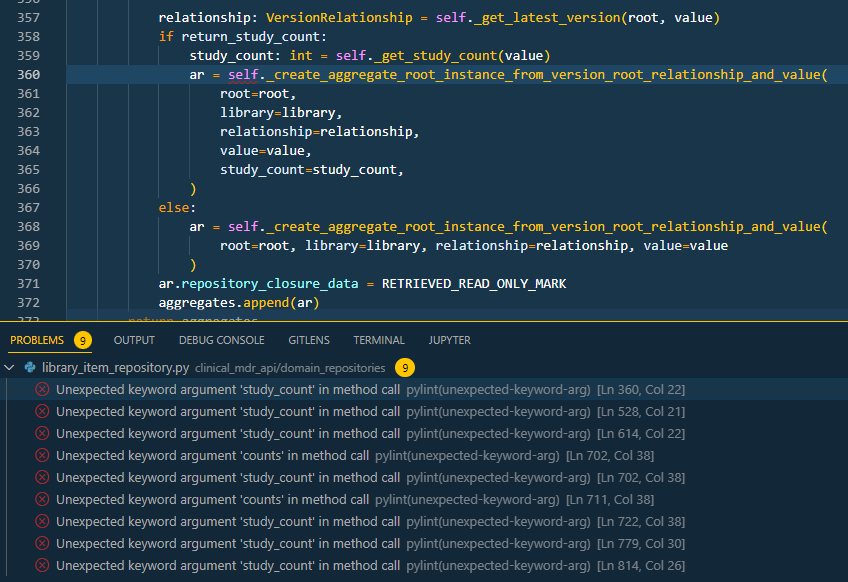
However, if you have a multi-root workspace, VS Code will not be able to automatically detect pyproject.toml; therefore, you will need to manually specify its path in the settings.
Follow these steps to add the path:
- Open
.vscode/settings.jsonfile (create it if it doesn't exist). - Add the following item to the JSON object:
"python.linting.pylintArgs": [
"--rcfile=${workspaceFolder}/clinical-mdr-api/pyproject.toml"
]
# Source Code Management
We are using the 'Git-flow-Workflow' approach described here: https://www.atlassian.com/de/git/tutorials/comparing-workflows/gitflow-workflow
# Authentication setup
See clinical-mdr-api/doc/Auth.md on how to set up authentication and
role-based access control for clinical-mdr-api and OpenStudyBuilder UI.
# Data Objects Structure
Usual Data Objects Properties
| Section Flag | Data Object |
|---|---|
| BPELCONFIG | - |
| DESCRIPTION | X |
| DETAILS | X |
| DOCUMENTPERMISSIONS | - |
| DOCUMENTSECURITY | - |
| EXPRESSIONS | - |
| FIELDDEFINITIONS | X |
| FIELDVALUES | X |
| HISTORY | X |
| NAME | X |
| PARAMETERS | X |
| PERMISSIONS | - |
| PROPERTIES | X |
| RESULT_COLUMNS | - |
| SECURITY | - |
| SOURCE_PROPERTIES | X |
# Raw data structure
# Routers
- get_all
- get_specific
- get_deletion_dependencies
- get_selected
- get_audit_trial
- post
- patch
- change_order
- delete
# Service
- _transform_all_to_response_model
- _transform_single_to_response_model
- get_all_selection
- get_all_selection_within_object
- delete_selection
- set_new_order
- _transform_history_to_response_model
- get_specific_selection_audit_trail
- _get_specific_object_selection
- make_selection
- _patch_prepare_new_object
- patch_selection
- get_specific_selection
- get_all_selections_for_all_studies
# Repository
# StudyHistoryObject
# StudySelectionObjectRepository
- _db_result_to_dict
- _acquire_write_lock_study_value
- _retrieves_all_data
- _retrieves_all_data_within_object
- find_by_study
- find_by_object_nested_info
- _get_audit_node
- object_specific_exists_by_uid
- get_object_connected_to_other_object
- object_specific_has_connected_other_object
- save
- _remove_old_selection_if_exists
- _set_before_audit_info
- object_parameter_exists
- _add_new_selection
- generate_uid
- _get_selection_with_history
- find_selection_history
# Domain
- object_schema
- post_schema
- edit_schema